1. Introduction
This project brings object detection and segmentation to life using YOLOv8 (You Only Look Once, version 8), the latest generation of the YOLO deep learning framework. It delivers advanced computer vision functionality for identifying and segmenting objects in images, video files, and live camera streams.
Representing a significant advancement in object detection technology, YOLOv8 provides higher accuracy, faster performance, and a more user-friendly design compared to its predecessors. The project highlights real-world applications of YOLOv8 for both detection (drawing bounding boxes around objects) and segmentation (creating pixel-level masks), making it highly suitable for applications like security surveillance, autonomous driving systems, retail analytics, and industrial automation.
The system includes both a Command Line Interface (CLI) and a Python API, offering flexibility for different workflows. It handles batch processing for static images and videos, as well as real-time analysis through webcam input.
Core Features:
- Detection of objects in images and videos using bounding boxes
- Instance segmentation with detailed, pixel-level masks
- Real-time detection and segmentation through webcam feed
- Dual access modes: CLI and Python API
- Pre-trained models supporting 80+ object categories (COCO dataset)
2. Methodology / Approach
The project leverages YOLOv8's state-of-the-art architecture for object detection and segmentation tasks. YOLOv8 processes images in a single forward pass through the neural network, making it exceptionally fast while maintaining high accuracy.
2.1 YOLOv8 Architecture Overview
YOLOv8 represents a major evolution in the YOLO series, introducing several architectural improvements:
Backbone Network:
- CSPDarknet53 with Cross Stage Partial (CSP) connections
- Efficient feature extraction through residual connections
- Spatial Pyramid Pooling Fast (SPPF) for multi-scale feature aggregation
Neck Network:
- Path Aggregation Network (PAN) for feature pyramid construction
- Bottom-up and top-down feature fusion
- Enhanced information flow across different scales
Head Network (Detection):
- Anchor-free detection head
- Decoupled classification and regression branches
- Direct bounding box prediction without anchor boxes
Head Network (Segmentation):
- Additional mask prediction branch
- Prototype mask generation
- Instance-specific coefficient prediction
2.2 Object Detection Process
Object Detection uses YOLOv8 detection models (yolov8x.pt) to identify objects and draw bounding boxes around them. The model predicts:
- Class labels: Object category (80 COCO classes)
- Confidence scores: Detection certainty (0-1)
- Bounding box coordinates: (x, y, width, height) in image space
The detection process involves:
- Image preprocessing and resizing
- Feature extraction through backbone network
- Multi-scale feature fusion in neck
- Parallel classification and box regression
- Non-maximum suppression (NMS) for duplicate removal
- Post-processing to original image coordinates
2.3 Object Segmentation Process
Object Segmentation employs YOLOv8 segmentation models (yolov8x-seg.pt) to perform instance segmentation. Beyond detection, the model generates:
- Segmentation masks: Pixel-level classification for each instance
- Mask coefficients: Instance-specific parameters
- Prototype masks: Learned basis functions for mask generation
The segmentation process extends detection with:
- Prototype mask generation from feature maps
- Mask coefficient prediction per detected object
- Linear combination of prototypes weighted by coefficients
- Sigmoid activation for binary mask generation
- Mask upsampling to original image resolution
- Instance-level mask refinement
2.4 System Architecture
The system is organized into six independent functionalities:
- Object Detection in Photos: Static image processing with bounding boxes
- Object Segmentation in Photos: Static image processing with segmentation masks
- Object Detection in Videos: Video file processing with detection
- Object Segmentation in Videos: Video file processing with segmentation
- Real-time Object Detection: Live camera feed detection
- Real-time Object Segmentation: Live camera feed segmentation
2.5 Implementation Strategy
Each functionality can be executed through either CLI commands or Python scripts, providing flexibility for different use cases. The CLI approach is ideal for quick testing and batch processing, while the Python API allows for integration into larger applications and custom workflows.
All operations use pre-trained YOLOv8 models capable of detecting 80 different object classes from the COCO dataset. The models are optimized for:
- Speed: Single-stage detection eliminates region proposal overhead
- Accuracy: Advanced feature fusion and anchor-free design
- Flexibility: Unified architecture for detection and segmentation
- Scalability: Multiple model sizes (n, s, m, l, x) for different requirements
3. Mathematical Framework
3.1 YOLOv8 Detection Algorithm
YOLOv8 divides the input image into an $S \times S$ grid and predicts bounding boxes directly without anchor boxes:
Grid Cell Prediction: For each grid cell $(i, j)$, the model predicts:
$$\mathbf{P}_{ij} = [\hat{x}, \hat{y}, \hat{w}, \hat{h}, \text{conf}, c_1, c_2, ..., c_n]$$
where:
- $(\hat{x}, \hat{y})$ = predicted box center relative to grid cell
- $(\hat{w}, \hat{h})$ = predicted box width and height
- $\text{conf}$ = objectness confidence score
- $c_i$ = class probabilities for $n$ classes
3.2 Bounding Box Transformation
The model predicts offsets that are transformed to absolute coordinates:
$$x = \sigma(\hat{x}) + c_x$$
$$y = \sigma(\hat{y}) + c_y$$
$$w = p_w \cdot e^{\hat{w}}$$
$$h = p_h \cdot e^{\hat{h}}$$
where:
- $\sigma$ = sigmoid activation function
- $(c_x, c_y)$ = grid cell top-left coordinates
- $(p_w, p_h)$ = prior dimensions (learned during training)
3.3 Intersection over Union (IoU)
IoU measures the overlap between predicted box $B_p$ and ground truth box $B_{gt}$:
$$\text{IoU}(B_p, B_{gt}) = \frac{\text{Area}(B_p \cap B_{gt})}{\text{Area}(B_p \cup B_{gt})}$$
Complete IoU (CIoU) Loss: YOLOv8 uses CIoU for bounding box regression:
$$\mathcal{L}_{\text{CIoU}} = 1 - \text{IoU} + \frac{\rho^2(\mathbf{b}, \mathbf{b}^{gt})}{c^2} + \alpha v$$
where:
- $\rho$ = Euclidean distance between box centers
- $c$ = diagonal length of the smallest enclosing box
- $v$ = aspect ratio consistency term
- $\alpha$ = trade-off parameter
3.4 Loss Functions
Total Loss:
$$\mathcal{L}_{\text{total}} = \lambda_{\text{box}} \mathcal{L}_{\text{box}} + \lambda_{\text{cls}} \mathcal{L}_{\text{cls}} + \lambda_{\text{dfl}} \mathcal{L}_{\text{dfl}}$$
Box Loss (CIoU):
$$\mathcal{L}_{\text{box}} = \sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{1}_{ij}^{\text{obj}} \, \mathcal{L}_{\text{CIoU}}(B_{ij}, \hat{B}_{ij})$$
Classification Loss (Binary Cross-Entropy):
$$\mathcal{L}_{\text{cls}} = -\sum_{i=0}^{S^2} \sum_{j=0}^{B} \mathbb{1}_{ij}^{\text{obj}} \sum_{c \in \text{classes}} \left[ p_c \log(\hat{p}_c) + (1-p_c)\log(1-\hat{p}_c) \right]$$
Distribution Focal Loss (DFL):
$$\mathcal{L}_{\text{dfl}} = -\sum_{i=0}^{n} (y_i + 1 - y) \log(S_i) - (y - y_i) \log(S_{i+1})$$
where $S$ is the softmax probability distribution for box regression.
3.5 Non-Maximum Suppression (NMS)
NMS eliminates duplicate detections by suppressing boxes with high IoU overlap:
Algorithm:
- Sort all detections by confidence score (descending)
- Select detection with highest confidence as output
- Remove all detections with $\text{IoU} > \text{threshold}$ (typically 0.45)
- Repeat until no detections remain
Mathematical Formulation:
$$\mathcal{D} = \{B_1, B_2, ..., B_n\} \quad \text{(sorted by confidence)}$$
$$\mathcal{D}_{\text{keep}} = \{B_i \in \mathcal{D} \mid \text{IoU}(B_i, B_j) < \tau, \, \forall B_j \in \mathcal{D}_{\text{keep}}, \, \text{conf}(B_i) < \text{conf}(B_j)\}$$
where $\tau$ is the NMS threshold.
3.6 Segmentation Mask Generation (YOLOv8-seg)
For instance segmentation, YOLOv8 predicts mask coefficients and combines them with prototype masks:
Prototype Masks: The neck network generates $k$ prototype masks:
$$\mathbf{P} = \{\mathbf{P}_1, \mathbf{P}_2, ..., \mathbf{P}_k\} \in \mathbb{R}^{k \times H \times W}$$
Mask Coefficients: For each detected instance, predict coefficient vector:
$$\mathbf{c}_i = [c_{i1}, c_{i2}, ..., c_{ik}] \in \mathbb{R}^k$$
Final Mask: Linear combination followed by sigmoid activation:
$$\mathbf{M}_i = \sigma\left(\sum_{j=1}^{k} c_{ij} \cdot \mathbf{P}_j\right)$$
where $\mathbf{M}_i \in [0,1]^{H \times W}$ is the binary mask for instance $i$.
Mask Loss (Binary Cross-Entropy):
$$\mathcal{L}_{\text{mask}} = -\frac{1}{HW} \sum_{x,y} \left[ m_{xy} \log(\hat{m}_{xy}) + (1-m_{xy})\log(1-\hat{m}_{xy}) \right]$$
where $m_{xy}$ is ground truth mask and $\hat{m}_{xy}$ is predicted mask at pixel $(x,y)$.
3.7 Confidence Score Calculation
The final detection confidence combines objectness and class probability:
$$\text{Score} = \text{Objectness} \times \text{Class Probability}$$
$$\text{Score}_c = P(\text{Object}) \times P(\text{Class}=c \mid \text{Object})$$
Detections with $\text{Score}_c < \text{threshold}$ (typically 0.25) are filtered out.
4. Requirements
requirements.txt
ultralytics>=8.0.05. Installation & Configuration
5.1 Environment Setup
# Clone the repository
git clone https://github.com/kemalkilicaslan/Object-Detection-and-Segmentation-with-YOLOv8.git
cd Object-Detection-and-Segmentation-with-YOLOv8
# Install required package
pip install -r requirements.txt5.2 Project Structure
Object-Detection-and-Segmentation-with-YOLOv8
├── Object-Detection-with-YOLOv8/
├── Object-Segmentation-with-YOLOv8/
├── README.md
├── requirements.txt
└── LICENSE5.3 Required Files
Pre-trained Models (automatically downloaded on first use):
yolov8x.pt- YOLOv8 extra-large detection modelyolov8x-seg.pt- YOLOv8 extra-large segmentation model
Input Files:
- Images:
.jpg,.png,.webpformats - Videos:
.mp4,.avi,.movformats - Camera: Webcam device (source=0)
6. Usage / How to Run
6.1 Object Detection in Photo
CLI:
yolo detect predict model=yolov8x.pt source="img.jpg" save=TruePython:
from ultralytics import YOLO
model = YOLO('yolov8x.pt')
results = model('img.jpg', save=True)6.2 Object Segmentation in Photo
CLI:
yolo task=segment mode=predict model=yolov8x-seg.pt source='img.jpg' save=truePython:
from ultralytics import YOLO
model = YOLO('yolov8x-seg.pt')
results = model('img.jpg', save=True)6.3 Object Detection in Video
CLI:
yolo detect predict model=yolov8x.pt source="video.mp4" save=TruePython:
from ultralytics import YOLO
model = YOLO('yolov8x.pt')
results = model('video.mp4', save=True)6.4 Object Segmentation in Video
CLI:
yolo task=segment mode=predict model=yolov8x-seg.pt source='video.mp4' save=truePython:
from ultralytics import YOLO
model = YOLO('yolov8x-seg.pt')
results = model('video.mp4', save=True)6.5 Real-Time Object Detection
CLI:
yolo detect predict model=yolov8x.pt source=0 show=TruePython:
from ultralytics import YOLO
model = YOLO('yolov8x.pt')
model.predict(source="0", show=True)Controls:
- Press
qorEscto quit the application - Requires active webcam (camera index 0)
6.6 Real-Time Object Segmentation
CLI:
yolo task=segment mode=predict model=yolov8x-seg.pt source='0' show=TruePython:
from ultralytics import YOLO
model = YOLO('yolov8x-seg.pt')
model.predict(source="0", show=True)7. Application / Results
7.1 Object Detection in Photo
Input Image:

Output Image:
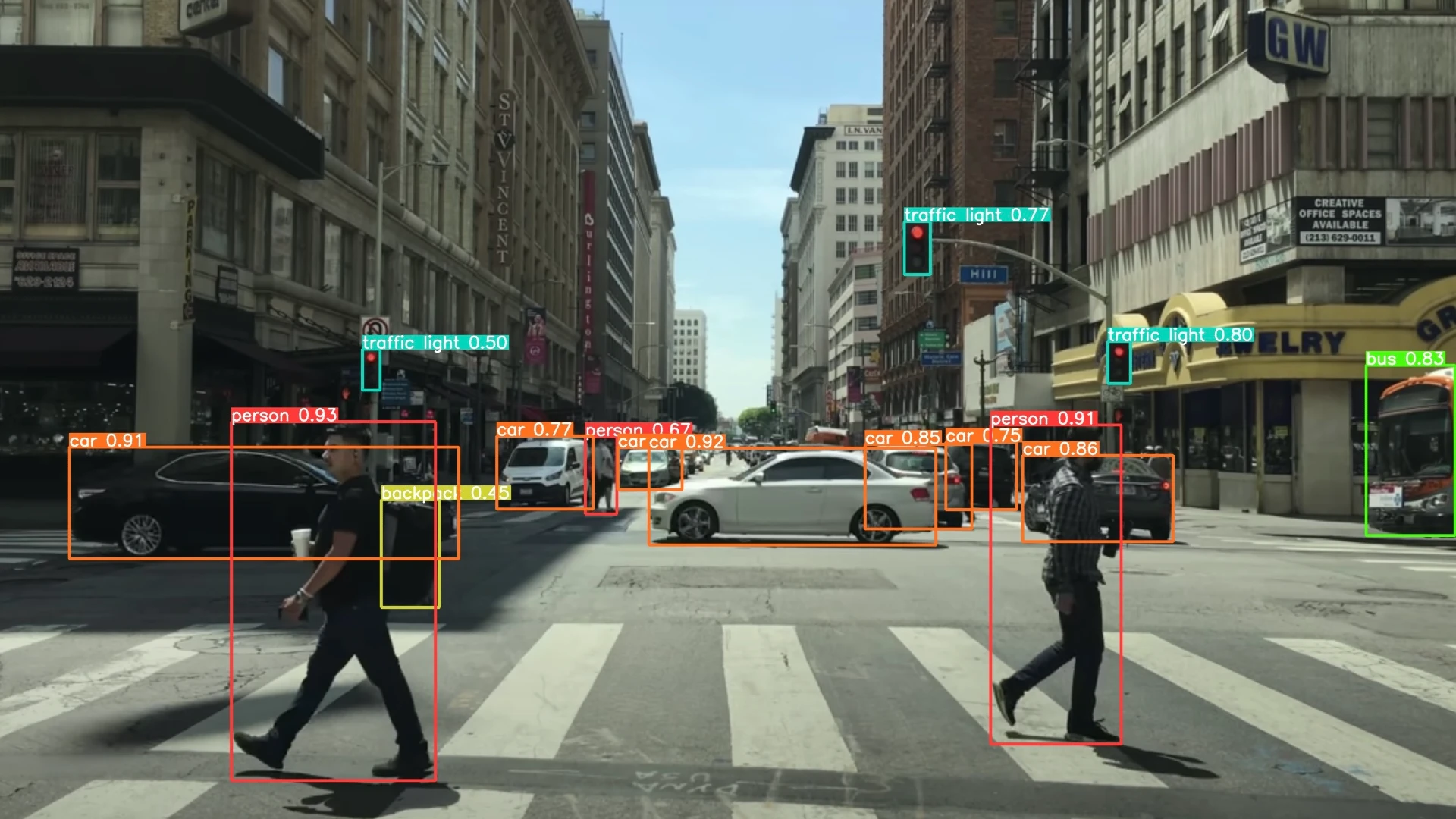
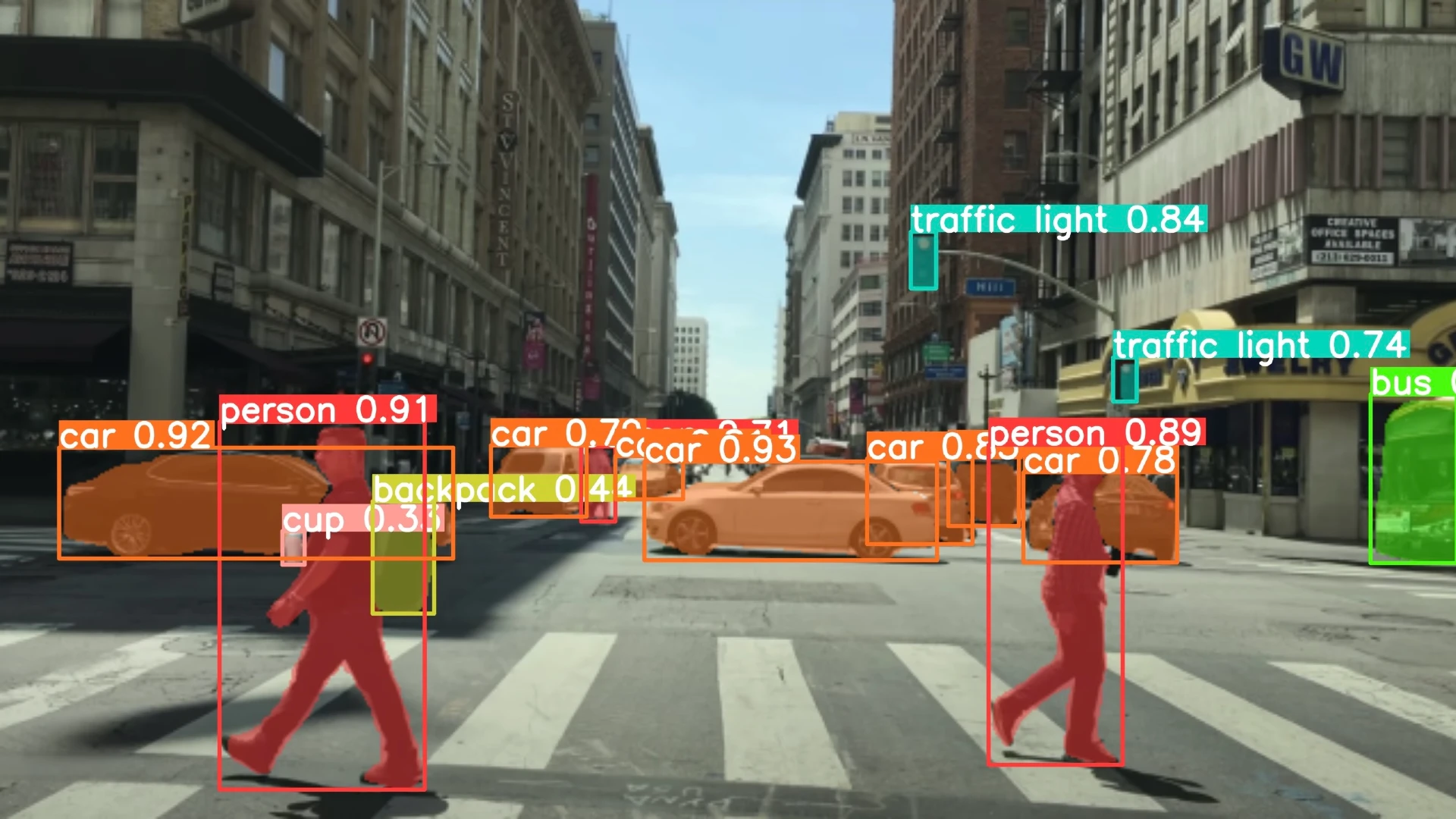
7.2 Object Segmentation in Photo
Input Image:
Output Image:
7.3 Object Detection in Video
Input Video:
Output Video:
7.4 Object Segmentation in Video
Input Video:
Output Video:
7.5 Real-Time Object Detection
Demo Video:
7.6 Real-Time Object Segmentation
Demo Video:
7.7 Performance Metrics
Performance varies based on hardware, model size, and input resolution:
| Metric | Object Detection | Object Segmentation |
|---|---|---|
| Processing Speed (GPU) | 50-100+ FPS | 30-60 FPS |
| Processing Speed (CPU) | 5-15 FPS | 2-8 FPS |
| Detection Accuracy (mAP) | 53.9% (COCO) | 52.3% (COCO) |
| Supported Classes | 80 (COCO dataset) | 80 (COCO dataset) |
Model Comparison:
| Model Size | Parameters | Speed (ms) | mAP50 | mAP50-95 |
|---|---|---|---|---|
| YOLOv8n | 3.2M | 1.5 | 37.3% | 28.4% |
| YOLOv8s | 11.2M | 2.3 | 44.9% | 36.2% |
| YOLOv8m | 25.9M | 4.5 | 50.2% | 42.8% |
| YOLOv8l | 43.7M | 6.8 | 52.9% | 45.7% |
| YOLOv8x | 68.2M | 9.2 | 53.9% | 47.1% |
8. Tech Stack
8.1 Core Technologies
- Programming Language: Python 3.8+
- Deep Learning Framework: Ultralytics YOLOv8
- Object Detection/Segmentation: YOLOv8 architecture
- Model Format: PyTorch (.pt)
8.2 Libraries & Dependencies
| Library | Version | Purpose |
|---|---|---|
| ultralytics | 8.0+ | YOLOv8 implementation, model training, and inference |
8.3 Pre-trained Models
YOLOv8 Detection Models:
- Model:
yolov8x.pt(extra-large) - Architecture: YOLOv8 detection
- Training: COCO dataset (80 object classes)
- Task: Object detection with bounding boxes
- Parameters: 68.2M
- Input: 640×640×3
- Output: Bounding boxes, class labels, confidence scores
YOLOv8 Segmentation Models:
- Model:
yolov8x-seg.pt(extra-large) - Architecture: YOLOv8 instance segmentation
- Training: COCO dataset (80 object classes)
- Task: Object segmentation with pixel masks
- Parameters: 71.8M
- Input: 640×640×3
- Output: Segmentation masks, bounding boxes, class labels
Supported Object Classes (COCO): person, bicycle, car, motorcycle, airplane, bus, train, truck, boat, traffic light, fire hydrant, stop sign, parking meter, bench, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe, backpack, umbrella, handbag, tie, suitcase, frisbee, skis, snowboard, sports ball, kite, baseball bat, baseball glove, skateboard, surfboard, tennis racket, bottle, wine glass, cup, fork, knife, spoon, bowl, banana, apple, sandwich, orange, broccoli, carrot, hot dog, pizza, donut, cake, chair, couch, potted plant, bed, dining table, toilet, tv, laptop, mouse, remote, keyboard, cell phone, microwave, oven, toaster, sink, refrigerator, book, clock, vase, scissors, teddy bear, hair drier, toothbrush.
9. License
This project is open source and available under the Apache License 2.0.
10. References
- Ultralytics YOLOv8 Documentation.
- Jocher, G., et al. (2024). Ultralytics YOLO GitHub Repository.
Acknowledgments
Special thanks to the Ultralytics team for developing and maintaining YOLOv8, making state-of-the-art object detection and segmentation accessible to everyone. This project builds upon the COCO dataset and the extensive research in computer vision that has enabled these capabilities.
Note: This project uses pre-trained models for demonstration purposes. For production applications, consider fine-tuning models on domain-specific datasets and ensuring compliance with relevant regulations regarding computer vision and AI systems.